In case you missed it, I figured out how to run my own binaries on my Haswell GPU. Since then I’ve gone off and wrote myself an assembler, of sorts. It’s a very high level assembler, and has a few nicities like named registers and predication using curly-brace blocks around instructions. It’s worked out well for what I really wanted to do, which was do some experiments. I wanted to see how far we could go by programming the GEN architecture directly in non-standard ways, and the assembler makes development of my renegade kernels much, much easier.
Having built myself some rudimentary tools, I thought I’d go see if I could leverage some of the untapped potential in this machine to make compute tasks go faster. This is less about second-guessing their GLSL compiler and more about demonstrating something I’ve heard often from Intel friends, which is that the current programming model for GPUs is deficient and leaves performance on the floor. We’re going to see that significant gains are possible by changing the way we program.
I’ve written two microbenchmarks that I’ll go through in this post. All code can be found here.
A Tale of Two Programming Models
Let’s start by motivating the discussion and talking about SIMD. For those of you who skipped your computer architecture class, SIMD stands for Single Instruction Mulitiple Data. A SIMD machine is a machine that issues one instruction which operates on multiple independent data elements in lock-step. There are two different programming models that I’ve used to target a SIMD machine.
The Explicit SIMD Model
In this model, we write code which directly manipulates vectors of various lengths. The obvious examples are the use of SSE, Neon, or Altivec extensions in C or C++. There is one thread of execution, and this thread can execute instructions that do multiple computations at once, and can also do bulk load/store of vector elements to contiguous memory. Some machines also support scatter/gather operations, where elements are loaded or stored from different addresses per lane.
The SPMD Model
Examples include GLSL, OpenCL, DirectCompute, and ISPC. Different colored vendors are going to use different acronyms to describe this thing. Some people say SPMD, for Single Program Multiple Data, others prefer the term Single Instruction Mulitple Thread (SIMT) but its all pretty much the same thing. Whatever we call it, the program is specified in terms of what happens in a single isolated thread.
The term thread in this context is horribly ambiguous. It is used in the languages and APIs to refer to a SIMD lane, but at the hardware level, it’s more natural to refer to a thread as a flow of control. The terms warp,wavefront, and hardware thread are used by different colored vendors to disambiguate a control flow from a SIMD lane. OpenCL uses work item to refer to a single lane, which is a better term.
Pretty much all implementations of SPMD languages will operate by mapping work items onto SIMD lanes, and implement control flow by masking inactive lanes, but SIMD is not fundamental to how the programming model works. If we wanted we could implement these SPMD languages using very large MIMD machines (CPU clusters) without any SIMD at all.
Example 1: Block Min/Max
My first test case is taking a scalar image and computing the min and max over 4×4 tiles. This is the first half of a BC4 compressor. I was going to write the entire compressor, but I got lazy and decided to only analyze the first part of it. GLSL code is shown below. Note that this could probably be a lot more efficient if we used images and gather4 operations, but I haven’t done the legwork of handling textures in my compute shader framework yet. Using gathers, I suspect, could be made to benefit everything equally.
layout (local_size_x = 16) in; layout (std430,binding=0) buffer Consts { uint g_nWidth; uint g_nHeight; uint g_nTIDShift; uint g_nTIDMask; }; layout (std430,binding=1) buffer InputImage { float g_Pixels[]; }; layout (std430,binding=2) buffer OutputBlocks { vec2 g_Blocks[]; }; vec4 Fetch4( uvec4 offs ) { vec4 block; block.x = g_Pixels[ offs.x ]; block.y = g_Pixels[ offs.y ]; block.z = g_Pixels[ offs.z ]; block.w = g_Pixels[ offs.w ]; return block; } void main() { // NOTE: Doing this with 1D indexing since that's what HAXWell supports // 2D might be a little better uint tid = gl_GlobalInvocationID.x; uvec2 vBlockIdx = uvec2( tid &g_nTIDMask, tid >> g_nTIDShift ); uvec2 vCorner = vBlockIdx*4; uvec4 base = uvec4( vCorner.y*g_nWidth + vCorner.x ); uvec4 offs0 = base + uvec4( 0, 1, 2, 3 ) ; uvec4 offs1 = offs0 + uvec4( g_nWidth ); uvec4 offs2 = offs1 + uvec4( g_nWidth ); uvec4 offs3 = offs2 + uvec4( g_nWidth ); vec4 block0 = Fetch4( offs0 ); vec4 block1 = Fetch4( offs1 ); vec4 block2 = Fetch4( offs2 ); vec4 block3 = Fetch4( offs3 ); // Find the Min and Max values vec4 lo4 = min(min(block0, block1), min(block2, block3)); vec4 hi4 = max(max(block0, block1), max(block2, block3)); float lo = min(min(lo4.x, lo4.y), min(lo4.z, lo4.w)); float hi = max(max(hi4.x, hi4.y), max(hi4.z, hi4.w)); g_Blocks[ tid ] = vec2(lo,hi); } |
I’ll compare this compute shader with two hand-written versions. One a direct re-implementation of the GLSL shader (16 threads, one in each lane), the other using explicit SIMD and thread-level programming.
Here are the results:

Here’s what the GLSL compiler does with our compute shader:
mov(8) r69.u<8,8,1>, 0 mul(1) r17.u<1,1,1>, r0.u1<0,1,0>, 16 mov(8) r127.u<8,8,1>, r0.u<8,8,1> send(8) UntypedRead(57) r53.u, r69.u add(16) r17.u<16,16,1>, r17.u<0,1,0>, r1.u<8,8,1> shr(16) r65.u<16,16,1>, r17.u<8,8,1>, r55.u<0,1,0> and(16) r67.u<16,16,1>, r17.u<8,8,1>, r56.u<0,1,0> mul(16) r63.u<16,16,1>, r65.u<8,8,1>, 4 mul(16) r59.u<16,16,1>, r67.u<8,8,1>, 4 mul(8) acc00.u<8,8,1>, r63.u<8,8,1>, r53.u<0,1,0> mach(0) null0.u, r63.u, r53.u mov(8) r57.u<8,8,1>, acc00.u<8,8,1> mul(8) acc00.u<8,8,1>, r64.u<8,8,1>, r53.u<0,1,0> mach(0) r61.u, r64.u, r53.u mov(8) r61.u<8,8,1>, acc00.u<8,8,1> mov(8) r58.u<8,8,1>, r61.u<8,8,1> add(16) r51.s<16,16,1>, r57.s<8,8,1>, r59.s<8,8,1> add(16) r47.s<16,16,1>, r51.s<8,8,1>, 1 add(16) r35.s<16,16,1>, r51.s<8,8,1>, r53.s<0,1,0> add(16) r43.s<16,16,1>, r51.s<8,8,1>, 2 mul(16) r49.s<16,16,1>, r51.s<8,8,1>, 4 add(16) r31.s<16,16,1>, r47.s<8,8,1>, r53.s<0,1,0> mul(16) r33.s<16,16,1>, r35.s<8,8,1>, 4 add(16) r39.s<16,16,1>, r51.s<8,8,1>, 3 mul(16) r45.s<16,16,1>, r47.s<8,8,1>, 4 add(16) r27.s<16,16,1>, r43.s<8,8,1>, r53.s<0,1,0> send(16) UntypedRead(56) r87.us, r49.us mul(16) r29.s<16,16,1>, r31.s<8,8,1>, 4 send(16) UntypedRead(56) r89.us, r33.us add(16) r19.s<16,16,1>, r35.s<8,8,1>, r53.s<0,1,0> mul(16) r41.s<16,16,1>, r43.s<8,8,1>, 4 add(16) r23.s<16,16,1>, r39.s<8,8,1>, r53.s<0,1,0> send(16) UntypedRead(56) r83.us, r45.us mul(16) r25.s<16,16,1>, r27.s<8,8,1>, 4 send(16) UntypedRead(56) r85.us, r29.us add(16) r13.s<16,16,1>, r31.s<8,8,1>, r53.s<0,1,0> mul(16) r37.s<16,16,1>, r39.s<8,8,1>, 4 add(16) r121.s<16,16,1>, r19.s<8,8,1>, r53.s<0,1,0> send(16) UntypedRead(56) r79.us, r41.us mul(16) r21.s<16,16,1>, r23.s<8,8,1>, 4 send(16) UntypedRead(56) r81.us, r25.us add(16) r9.s<16,16,1>, r27.s<8,8,1>, r53.s<0,1,0> mul(16) r15.s<16,16,1>, r19.s<8,8,1>, 4 add(16) r117.s<16,16,1>, r13.s<8,8,1>, r53.s<0,1,0> send(16) UntypedRead(56) r75.us, r37.us mul(16) r119.s<16,16,1>, r121.s<8,8,1>, 4 send(16) UntypedRead(56) r77.us, r21.us add(16) r125.s<16,16,1>, r23.s<8,8,1>, r53.s<0,1,0> mul(16) r11.s<16,16,1>, r13.s<8,8,1>, 4 add(16) r113.s<16,16,1>, r9.s<8,8,1>, r53.s<0,1,0> send(16) UntypedRead(56) r71.us, r15.us mul(16) r115.s<16,16,1>, r117.s<8,8,1>, 4 send(16) UntypedRead(56) r73.us, r119.us mul(16) r7.s<16,16,1>, r9.s<8,8,1>, 4 add(16) r109.s<16,16,1>, r125.s<8,8,1>, r53.s<0,1,0> send(16) UntypedRead(56) r67.us, r11.us mul(16) r111.s<16,16,1>, r113.s<8,8,1>, 4 send(16) UntypedRead(56) r69.us, r115.us mul(16) r123.s<16,16,1>, r125.s<8,8,1>, 4 send(16) UntypedRead(56) r63.us, r7.us mul(16) r107.s<16,16,1>, r109.s<8,8,1>, 4 send(16) UntypedRead(56) r65.us, r111.us send(16) UntypedRead(56) r59.us, r123.us send(16) UntypedRead(56) r61.us, r107.us mul(16) r15.s<16,16,1>, r17.s<8,8,1>, 8 add(16) r13.s<16,16,1>, r15.s<8,8,1>, 4 add(16) r7.s<16,16,1>, r13.s<8,8,1>, -4 sel(16) r103.f<16,16,1>, r87.f<8,8,1>, r89.f<8,8,1> cm(lt) sel(16) r99.f<16,16,1>, r83.f<8,8,1>, r85.f<8,8,1> cm(lt) sel(16) r95.f<16,16,1>, r79.f<8,8,1>, r81.f<8,8,1> cm(lt) sel(16) r91.f<16,16,1>, r75.f<8,8,1>, r77.f<8,8,1> cm(lt) sel(16) r105.f<16,16,1>, r71.f<8,8,1>, r73.f<8,8,1> cm(lt) sel(16) r101.f<16,16,1>, r67.f<8,8,1>, r69.f<8,8,1> cm(lt) sel(16) r97.f<16,16,1>, r63.f<8,8,1>, r65.f<8,8,1> cm(lt) sel(16) r93.f<16,16,1>, r59.f<8,8,1>, r61.f<8,8,1> cm(lt) sel(16) r39.f<16,16,1>, r103.f<8,8,1>, r105.f<8,8,1> cm(lt) sel(16) r41.f<16,16,1>, r99.f<8,8,1>, r101.f<8,8,1> cm(lt) sel(16) r35.f<16,16,1>, r95.f<8,8,1>, r97.f<8,8,1> cm(lt) sel(16) r37.f<16,16,1>, r91.f<8,8,1>, r93.f<8,8,1> cm(lt) sel(16) r55.f<16,16,1>, r87.f<8,8,1>, r89.f<8,8,1> cm(ge) sel(16) r51.f<16,16,1>, r83.f<8,8,1>, r85.f<8,8,1> cm(ge) sel(16) r47.f<16,16,1>, r79.f<8,8,1>, r81.f<8,8,1> cm(ge) sel(16) r43.f<16,16,1>, r75.f<8,8,1>, r77.f<8,8,1> cm(ge) sel(16) r57.f<16,16,1>, r71.f<8,8,1>, r73.f<8,8,1> cm(ge) sel(16) r53.f<16,16,1>, r67.f<8,8,1>, r69.f<8,8,1> cm(ge) sel(16) r49.f<16,16,1>, r63.f<8,8,1>, r65.f<8,8,1> cm(ge) sel(16) r45.f<16,16,1>, r59.f<8,8,1>, r61.f<8,8,1> cm(ge) sel(16) r27.f<16,16,1>, r55.f<8,8,1>, r57.f<8,8,1> cm(ge) sel(16) r29.f<16,16,1>, r51.f<8,8,1>, r53.f<8,8,1> cm(ge) sel(16) r23.f<16,16,1>, r47.f<8,8,1>, r49.f<8,8,1> cm(ge) sel(16) r25.f<16,16,1>, r43.f<8,8,1>, r45.f<8,8,1> cm(ge) sel(16) r31.f<16,16,1>, r39.f<8,8,1>, r41.f<8,8,1> cm(lt) sel(16) r33.f<16,16,1>, r35.f<8,8,1>, r37.f<8,8,1> cm(lt) sel(16) r9.f<16,16,1>, r31.f<8,8,1>, r33.f<8,8,1> cm(lt) sel(16) r19.f<16,16,1>, r27.f<8,8,1>, r29.f<8,8,1> cm(ge) sel(16) r21.f<16,16,1>, r23.f<8,8,1>, r25.f<8,8,1> cm(ge) sel(16) r11.f<16,16,1>, r19.f<8,8,1>, r21.f<8,8,1> cm(ge) send(16) UntypedWrite(58) null0.us, r7.us send(8) desc=0x02000010 dst=SPAWNER null0.u, r127.u |
As you can see, we have 16 loads, one for each pixel in a 4×4 block, followed by 30 min/max instructions (15 each for min and max). This is what you get when you take a single-threaded reduction and simply spread it across lanes. You’ll also notice that the driver’s GLSL compiler is a little bit nutty on address arithmetic, emitting such oddities as:
mul(16) r15.s<16,16,1>, r17.s<8,8,1>, 8 add(16) r13.s<16,16,1>, r15.s<8,8,1>, 4 add(16) r7.s<16,16,1>, r13.s<8,8,1>, -4 |
The hand-written version (SPMD16) does about 30% less compute, but runs at more or less the same speed, so I suspect the shader to be bottlenecked by cache access. I tried SPMD8 as well, it is terrible and not worth presenting.
Here is the code produced by my assembler for SPMD16. I’m posting the assembled output here for conciseness, but you may find the source code more readable.
mov(8) r127.u<8,8,1>, r0.u<8,8,1> send(8) DwordScatterRead(56) r51.u, r1.u mul(16) r56.u<16,16,1>, r0.u1<0,1,0>, 16 add(16) r56.u<16,16,1>, r56.u<8,8,1>, r1.u<8,8,1> shr(16) r54.u<16,16,1>, r56.u<8,8,1>, r51.u2<0,1,0> and(16) r52.u<16,16,1>, r56.u<8,8,1>, r51.u3<0,1,0> mul(16) r54.u<16,16,1>, r54.u<8,8,1>, 4 mul(16) r52.u<16,16,1>, r52.u<8,8,1>, 4 mul(16) r43.u<16,16,1>, r54.u<8,8,1>, r51.u<0,1,0> add(16) r43.u<16,16,1>, r52.u<8,8,1>, r43.u<8,8,1> send(16) DwordScatterRead(57) r3.u, r43.u add(16) r45.u<16,16,1>, r43.u<8,8,1>, 1 send(16) DwordScatterRead(57) r5.u, r45.u add(16) r47.u<16,16,1>, r43.u<8,8,1>, 2 send(16) DwordScatterRead(57) r7.u, r47.u add(16) r49.u<16,16,1>, r43.u<8,8,1>, 3 send(16) DwordScatterRead(57) r9.u, r49.u add(16) r43.u<16,16,1>, r43.u<8,8,1>, r51.u<0,1,0> send(16) DwordScatterRead(57) r11.u, r43.u add(16) r45.u<16,16,1>, r45.u<8,8,1>, r51.u<0,1,0> send(16) DwordScatterRead(57) r13.u, r45.u add(16) r47.u<16,16,1>, r47.u<8,8,1>, r51.u<0,1,0> send(16) DwordScatterRead(57) r15.u, r47.u add(16) r49.u<16,16,1>, r49.u<8,8,1>, r51.u<0,1,0> send(16) DwordScatterRead(57) r17.u, r49.u add(16) r43.u<16,16,1>, r43.u<8,8,1>, r51.u<0,1,0> send(16) DwordScatterRead(57) r19.u, r43.u add(16) r45.u<16,16,1>, r45.u<8,8,1>, r51.u<0,1,0> send(16) DwordScatterRead(57) r21.u, r45.u add(16) r47.u<16,16,1>, r47.u<8,8,1>, r51.u<0,1,0> send(16) DwordScatterRead(57) r23.u, r47.u add(16) r49.u<16,16,1>, r49.u<8,8,1>, r51.u<0,1,0> send(16) DwordScatterRead(57) r25.u, r49.u add(16) r43.u<16,16,1>, r43.u<8,8,1>, r51.u<0,1,0> send(16) DwordScatterRead(57) r27.u, r43.u add(16) r45.u<16,16,1>, r45.u<8,8,1>, r51.u<0,1,0> send(16) DwordScatterRead(57) r29.u, r45.u add(16) r47.u<16,16,1>, r47.u<8,8,1>, r51.u<0,1,0> send(16) DwordScatterRead(57) r31.u, r47.u add(16) r49.u<16,16,1>, r49.u<8,8,1>, r51.u<0,1,0> send(16) DwordScatterRead(57) r33.u, r49.u sel(16) r58.f<16,16,1>, r3.f<8,8,1>, r5.f<8,8,1> cm(le) sel(16) r62.f<16,16,1>, r3.f<8,8,1>, r5.f<8,8,1> cm(ge) sel(16) r60.f<16,16,1>, r7.f<8,8,1>, r9.f<8,8,1> cm(le) sel(16) r64.f<16,16,1>, r7.f<8,8,1>, r9.f<8,8,1> cm(ge) sel(16) r58.f<16,16,1>, r58.f<8,8,1>, r13.f<8,8,1> cm(le) sel(16) r62.f<16,16,1>, r62.f<8,8,1>, r13.f<8,8,1> cm(ge) sel(16) r60.f<16,16,1>, r60.f<8,8,1>, r15.f<8,8,1> cm(le) sel(16) r64.f<16,16,1>, r64.f<8,8,1>, r15.f<8,8,1> cm(ge) sel(16) r58.f<16,16,1>, r58.f<8,8,1>, r17.f<8,8,1> cm(le) sel(16) r62.f<16,16,1>, r62.f<8,8,1>, r17.f<8,8,1> cm(ge) sel(16) r60.f<16,16,1>, r60.f<8,8,1>, r19.f<8,8,1> cm(le) sel(16) r64.f<16,16,1>, r64.f<8,8,1>, r19.f<8,8,1> cm(ge) sel(16) r58.f<16,16,1>, r58.f<8,8,1>, r21.f<8,8,1> cm(le) sel(16) r62.f<16,16,1>, r62.f<8,8,1>, r21.f<8,8,1> cm(ge) sel(16) r60.f<16,16,1>, r60.f<8,8,1>, r23.f<8,8,1> cm(le) sel(16) r64.f<16,16,1>, r64.f<8,8,1>, r23.f<8,8,1> cm(ge) sel(16) r58.f<16,16,1>, r58.f<8,8,1>, r25.f<8,8,1> cm(le) sel(16) r62.f<16,16,1>, r62.f<8,8,1>, r25.f<8,8,1> cm(ge) sel(16) r60.f<16,16,1>, r60.f<8,8,1>, r27.f<8,8,1> cm(le) sel(16) r64.f<16,16,1>, r64.f<8,8,1>, r27.f<8,8,1> cm(ge) sel(16) r58.f<16,16,1>, r58.f<8,8,1>, r29.f<8,8,1> cm(le) sel(16) r62.f<16,16,1>, r62.f<8,8,1>, r29.f<8,8,1> cm(ge) sel(16) r60.f<16,16,1>, r60.f<8,8,1>, r31.f<8,8,1> cm(le) sel(16) r64.f<16,16,1>, r64.f<8,8,1>, r31.f<8,8,1> cm(ge) sel(16) r58.f<16,16,1>, r58.f<8,8,1>, r33.f<8,8,1> cm(le) sel(16) r62.f<16,16,1>, r62.f<8,8,1>, r33.f<8,8,1> cm(ge) sel(16) r60.f<16,16,1>, r60.f<8,8,1>, r11.f<8,8,1> cm(le) sel(16) r64.f<16,16,1>, r64.f<8,8,1>, r11.f<8,8,1> cm(ge) mul(16) r35.u<16,16,1>, r56.u<8,8,1>, 8 sel(16) r37.f<16,16,1>, r58.f<8,8,1>, r60.f<8,8,1> cm(le) sel(16) r39.f<16,16,1>, r62.f<8,8,1>, r64.f<8,8,1> cm(ge) send(16) UntypedWrite(58) null0.u, r35.u send(16) desc=0x02000010 dst=SPAWNER null0.u, r127.u |
And here is the explicit version:
mov(8) r127.u<8,8,1>, r0.u<8,8,1> send(8) DwordScatterRead(56) r47.u, r1.u mul(8) r50.u<8,8,1>, r0.u1<0,1,0>, 8 add(8) r50.u<8,8,1>, r50.u<8,8,1>, r1.u<8,8,1> shr(8) r49.u<8,8,1>, r50.u<8,8,1>, r47.u2<0,1,0> and(8) r48.u<8,8,1>, r50.u<8,8,1>, r47.u3<0,1,0> mul(8) r49.u<8,8,1>, r49.u<8,8,1>, 4 mul(8) r48.u<8,8,1>, r48.u<8,8,1>, 4 mul(8) r42.u<8,8,1>, r49.u<8,8,1>, r47.u<0,1,0> add(8) r42.u<8,8,1>, r48.u<8,8,1>, r42.u<8,8,1> add(4) r43.u<4,4,1>, r42.u<0,1,0>, r1.u<4,4,1> add(4) r43.u4<4,4,1>, r42.u1<0,1,0>, r1.u<4,4,1> add(4) r44.u<4,4,1>, r42.u2<0,1,0>, r1.u<4,4,1> add(4) r44.u4<4,4,1>, r42.u3<0,1,0>, r1.u<4,4,1> send(16) DwordScatterRead(57) r2.u, r43.u add(4) r45.u<4,4,1>, r42.u4<0,1,0>, r1.u<4,4,1> add(4) r45.u4<4,4,1>, r42.u5<0,1,0>, r1.u<4,4,1> add(4) r46.u<4,4,1>, r42.u6<0,1,0>, r1.u<4,4,1> add(4) r46.u4<4,4,1>, r42.u7<0,1,0>, r1.u<4,4,1> send(16) DwordScatterRead(57) r4.u, r45.u add(16) r43.u<16,16,1>, r43.u<8,8,1>, r47.u<0,1,0> send(16) DwordScatterRead(57) r6.u, r43.u add(16) r45.u<16,16,1>, r45.u<8,8,1>, r47.u<0,1,0> send(16) DwordScatterRead(57) r8.u, r45.u add(16) r43.u<16,16,1>, r43.u<8,8,1>, r47.u<0,1,0> send(16) DwordScatterRead(57) r10.u, r43.u add(16) r45.u<16,16,1>, r45.u<8,8,1>, r47.u<0,1,0> send(16) DwordScatterRead(57) r12.u, r45.u add(16) r43.u<16,16,1>, r43.u<8,8,1>, r47.u<0,1,0> send(16) DwordScatterRead(57) r14.u, r43.u add(16) r45.u<16,16,1>, r45.u<8,8,1>, r47.u<0,1,0> send(16) DwordScatterRead(57) r16.u, r45.u sel(16) r18.f<16,16,1>, r2.f<8,8,1>, r6.f<8,8,1> cm(le) sel(16) r20.f<16,16,1>, r4.f<8,8,1>, r8.f<8,8,1> cm(le) sel(16) r22.f<16,16,1>, r10.f<8,8,1>, r14.f<8,8,1> cm(le) sel(16) r24.f<16,16,1>, r12.f<8,8,1>, r16.f<8,8,1> cm(le) sel(16) r26.f<16,16,1>, r2.f<8,8,1>, r6.f<8,8,1> cm(ge) sel(16) r28.f<16,16,1>, r4.f<8,8,1>, r8.f<8,8,1> cm(ge) sel(16) r30.f<16,16,1>, r10.f<8,8,1>, r14.f<8,8,1> cm(ge) sel(16) r32.f<16,16,1>, r12.f<8,8,1>, r16.f<8,8,1> cm(ge) sel(16) r18.f<16,16,1>, r18.f<8,8,1>, r22.f<8,8,1> cm(le) sel(16) r20.f<16,16,1>, r20.f<8,8,1>, r24.f<8,8,1> cm(le) sel(16) r26.f<16,16,1>, r26.f<8,8,1>, r30.f<8,8,1> cm(ge) sel(16) r28.f<16,16,1>, r28.f<8,8,1>, r32.f<8,8,1> cm(ge) sel(8) r34.f<8,8,1>, r18.f<4,2,2>, r18.f<4,2,2> cm(le) sel(8) r35.f<8,8,1>, r20.f<4,2,2>, r20.f<4,2,2> cm(le) sel(8) r36.f<8,8,1>, r26.f<4,2,2>, r26.f<4,2,2> cm(ge) sel(8) r37.f<8,8,1>, r28.f<4,2,2>, r28.f<4,2,2> cm(ge) sel(8) r40.f<8,8,1>, r34.f<4,2,2>, r34.f<4,2,2> cm(le) sel(8) r41.f<8,8,1>, r36.f<4,2,2>, r36.f<4,2,2> cm(ge) mul(8) r38.u<8,8,1>, r50.u<8,8,1>, 2 add(8) r39.u<8,8,1>, r38.u<8,8,1>, 1 send(16) DwordScatterWrite(58) null0.u, r38.u send(16) desc=0x02000010 dst=SPAWNER null0.u, r127.u |
The explicit version does things differently. First-off, we run 8 blocks per thread instead of 16. Because we’re programming at the hardware thread level instead of the lane level, we can use SIMD16 instructions in our 8-wide computation, which should make it faster (relative to a SIMD8 SPMD implementation). This is especially important for the load/store messages, since we now need only half as many of them. Two SIMD8 reads can be combined into one SIMD16 message.
Second, rather than organize our loads based on their location in a given block, we can arrange them based on memory locality instead. Here’s how this works:
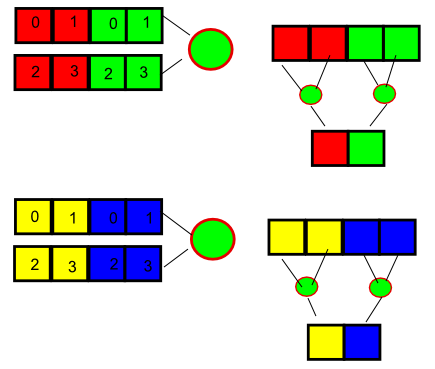
I’ll illustrate with 2×2 blocks and 4-wide SIMD, because it’s easier to draw. In the figure below, each color is a different pixel block, and let’s pretend that each row fits in one cache line.
An SPMD implementation loads pixels one by one, for different blocks, and reduces them vertically, one block in each lane, as shown below. In our example each load operation accesses 2 different cache lines. In the real shader with 4×4 pixel blocks and SIMD16, it’s actually 4 lines per load.

The explicit implementation can do better by using a combination of horizontal and vertical operations, and loading elements from the same block in the same load. This way, each load accesses only one cache line.
Even though the bandwidth is the same, better locality in the load messages means that they complete faster, because fewer lines need to be read to complete each request. Using 8 blocks per thread instead of 16 also means that the per-thread cache footprint is lower, which might also be helping. A similar re-ordering of the loads should be possible in an image/gather4 implementation.
The min/max calculation is no longer as simple in the explicit version, because it requires the ability to do horizontal operations across SIMD lanes. This is not a thing in most compute languages (though it does exist in OpenCL 2.0 and ISPC). Luckily, I’m coding directly to the ISA, and the Gen EU easily supports horizontal ops using its most unique and underutilized feature: register regioning. The hardware can do 8 pair-wise reductions across an input reg pair by using regioning and offsetting as shown:
// <4,2,2> regioning pattern selects alternating elements
//
// Given adjacent regs:
// reg0 = (0,1,2,3,4,5,6,7)
// reg1 = (8,9,10,11,12,13,14,15)
//
// An instruction: op(8) result.f, reg0.f<4,2,2>, reg0.f1<4,2,2>
// does: op( {0,2,4,6,8,10,12,14} , {1,3,5,7,9,11,13,15} )
// |
Example 2: N-Body
The second test case is an N body simulation. Given a set of N point masses, calculate the gravitational force they exert on each other, and then move them.
Again, 3 versions. The first is a naive one that does one body per thread and loops over all the others. The second uses a typical SPMD trick: using shared memory to amortize the cost of loading bodies. The third uses explicit SIMD in interesting ways. The code’s too long, I’m not going to post it. Find it here.
I don’t know if this implementation is numerically stable enough to be in real applications. It’s probably good enough for graphics, and it’s certainly good enough to be benchmarked, which is the part I really care about.
We’ll compare these two GLSL implementations to a third version which uses explicit SIMD. I should note that there are sporadic crashes and TDRs with the explicit version, which only occur when it’s run after the shared-memory version. Some instability is not surprising considering the evil things I’m doing in order to be able to run my own custom kernels. When it doesn’t crash, the explicit version produces results comparable to the GLSL version. There ARE differences in the output, but I believe they’re down to precision differences between the implementations.
Here are the timings:

Here, again, we get a healthy speedup from explicit SIMD.
Here’s how we did it: Since we’re using explicit SIMD we’re not constrained by the number of SIMD lanes. We can assign work to hardware threads however we want. So, instead of processing 16 bodies per thread, we process 64. We can do this, because Intel gives us 4KB of register space for every hardware thread, and there is no penalty for using all of it. I stopped at 64 because it was a nice large number and I’m allocating registers by hand, badly, but with some fine tuning it should be possible to fit even more.
We start off by pre-loading all of the body positions into registers in SoA form, groups of 8 registers each for X,Y, and Z. In our loop, we do one SIMD8 load per thread to pull in 2 bodies at a time. In contrast, the GLSL driver’s SPMD implementation does multiple load messages and broadcasts them to all SIMD lanes, because it can’t figure out that the load addresses are the same for all the bodies it’s computing. Having loaded our bodies, we then use broadcast register regioning to do all of the force calculations against the 64 bodies our thread owns. You can look at the code to see all the details. I also use predication to avoid applying a body’s gravitation to itself. The driver didn’t seem to want to do this but it seems logical, and might be to blame for part of my speedup.
The benefits of this implementation are twofold:
First, since we’re using the register file to hold more bodies, we can do the job in fewer passes over the dataset (N/64 instead of N/16). You could probably trick the driver into doing this particular optimization for you, but it’s likely to be an anti-optimization on non-intel due to reduced occupancy.
Second, since we’re using explicit SIMD, we can load data more efficiently in the inner loop, using one SIMD8 load per two test bodies, instead of multiple SIMD16 loads, each of which broadcasts the same data across lanes. The driver compiler could recognize this in theory, but in practice it does not.
What To Make Of All This?
These are not rock-solid results. I admit I’ve cut a lot of corners and left some room for doubt, but it looks like significant speedups are possible by using explicit thread-level programming. There are optimizations that can be done at this level which are simply not possible using a conventional SPMD model.
Let’s remember that all of this code that I have written SUCKS. It does not use registers perfectly. Many instructions are probably poorly scheduled. I got sloppy in a few places. There are probably various undocumented performance pitfalls I’m hitting. An actual compiler generating this code would probably be more better, but in order for a compiler to do it, we need a suitable programming model to build the compiler around.
What programming model should this be?
One option is to just go with explicit SIMD. Write the program at the hardware-thread level instead of the lane level, and use explicit vector operations. I don’t think it would be such a bad idea for Intel to build an intrinsics language for GEN, along the lines of AVX512. Design a syntax for thread-level programming on this GPU, either using a C variant with intrinsics, or as a massive OpenCL extension. Anybody who bothers to look at AVX for client applications would certainly have a use for something like this.
The problem with explicit SIMD is cross-vendor and cross-device portability. Programs written for a particular SIMD width can’t easily be mapped onto a wider one, and mapping onto a narrower one, while possible, might result in sub-optimal code. SPMD has a serious advantage in that it’s able to target AMD’s massive 64-wide SIMDs just as easily as Intel’s itty-bitty 8-wide ones, at least for simple usage patterns like do this operation on 1 million pixels. For simple stream processing applications, SPMD makes perfect sense, and it’s relatively easy to write one source code that will run close to optimal on all the architectures.
Things start to break down, though, once you start attempting to coordinate between groups of related “threads”. A fixed assignment of threads to thread groups, with manual barrier placement, has many of the same problems as explicit SIMD. It doesn’t give the implementation any semantic freedom to execute the work in the best possible way.
In Intel’s case, “best possible way” means using the massive register file whenever possible, and trying to do more within one hardware thread. Less parallelism, and maximum efficiency within a given thread. Unfortunately for them, this is not the way most GP-GPU code is written, because the API design is driven largely by competing GPUs with very different characteristics. Competing hardware favors the exact opposite approach: As many threads as possible, as few registers per thread as possible, and shared memory for cross-thread communication.
It is not reasonable to expect a driver to take my GLSL N-body shader and turn it into the 64-body version automatically. I told them use 16 threads in a group and launch N/16 groups, and it’s non-trivial for the driver to turn that into 64 and N/64 behind my back. You can’t hand the driver coffee and expect it to make tea.
It might be worthwhile to think about a new mental model for compute shaders, which allows us to express reduction and nested parallelism, while avoiding barriers and explicit grouping. A better model might be for me to say run this code on these 5000 things and have the compiler do what it likes, perhaps with some nudging by the programmer. This would probably bring the most benefit to Intel, but it could help the green and red teams as well by giving them more control over the warp/wavefront allocation.
Here’s some toy syntax I made up to illustrate the point. This obviously needs to percolate.
void BlockMinMax( uint num_blocks )
{
// dispatch an unknown number of work items
// compiler chooses item/HWThread mapping based on
// the amount of ILP or reg pressure in the block
//
fork( unsigned int tid : num_blocks )
{
// local variables might live in registers, shared memory, or both
// whatever the compiler decides makes sense
unsigned int bx = tid%block_width;
unsigned int by = tid/block_width;
unsigned int x = 4*bx;
unsigned int y = 4*by;
// run a fixed number of data-parallel jobs
// compiler might implement by looping in one HWThread, or
// by spreading across SIMD lanes.
//
// HW with SIMD width > 16 could choose to pack
// multiple outer loop iterations into a wave.
float fMin, fMax;
fork( unsigned int i : 16 )
{
uint yy = i/4;
uint xx = i%4;
float f = Image[ (y+yy)*width + (x+xx)];
reduce_min(fMin,f);
reduce_max(fMax,f);
}
Output[tid] = float2(fMin,fMax);
}
}
void Nbody( uint num_bodies )
{
// Outer fork could be:
// - one HWThread per body
// - one HWThread per 16 bodies
// - one HWThread per 64 bodies
// - 40 GCN waves per 2560 bodies (or whatever fits)
// all of this is up to the implementation.
// (although, hints of some sort might be a good idea).
fork( uint i: num_bodies )
{
float3 body = load_body(i);
float3 force=0;
// inner fork could be:
// - a loop inside of one HWThread, one body at a time
// - a loop inside of one HWThread, 64 bodies at a time
// - a full workgroup executing a strip-mined loop in parallel
// (load 2560 bodies into LDS, barrier, apply forces, repeat)
fork( uint j : num_bodies )
{
float3 bj = load_body(j);
float3 fi = calc_force(body,bj);
reduce_add(force,fi);
}
}
} |
Neatly exposing register regioning in Intel OpenCL would be really useful.
Perhaps modifying the Beignet compiler would be a good start.
You could imagine marking a kernel as being “GEN Native” which would present one hardware thread per 28KB register file. An extension API would then expose register-region’able instructions.
Alternatively, being able to inline access would be even better.
Perhaps a new data type “intel_grf” that must appear in a union and can be operated on by register-region instructions.
I think the community needs to drop the expectation of perfect portability if they really want performance and efficiency.
One can imagine a pre-prod phase where the compiler tries different “compilation configurations”, ultimately selecting the one with the best throughput (all the while keeping the output correct).
Dub this “dynamic compilation”